반응형
학창시절 과제 및 실습등을 하고 회사에서 프로젝트를 뛰며 데이터 전처리 작업은 필수인데, 이때 labeling 작업을 했는데 너무나도 시간이 많이 소요 되어 매번 무척 힘들었다.
나름 다양한 방법들을 시도 했지만 보통은 시간을 많이 요하는 작업이라서 매번 적합한 방법을 찾아서 사용하곤했다.
이러한것을 해결해보려고 Auto-labeling 기능이란걸 검색하다보니 Amazon SageMaker를 찾게되었는데, ML에 필요한 수많은 기능들이 있었다. 어디서 부터 해야할지 모르겠어서 원래는..접근도 못하였다. (AWS라는 기본적인 개념도 없어서 아예 접근을 못함..) 심지어 블로그에도 많은 내용이 나와있지는 않았고..
그런데 AWS에서 SageMaker Immersion Day를 한다고 하여 SageMaker가 무엇인지 대략적인거라도 알고 싶어서 참가하게 되었다.

아니 어떻게 딱 공부하려고 하니까 이런 기회가 찾아오는가.,,, 시간은 10시부터 5시까지였는데, 그 시간안에 SageMaker에 대한 전체적인 기능을 자세하게 알 수는 없었지만, 대략적으로 알게 되어서 잘 참가했다고 생각했다.
내가 배운것을 누군가도 알았으면 좋겠다고 항상 생각하여, 간략하게 SageMaker를 소개하고 사용 후기를 포스팅 해보려고한다
먼저 AI가 무엇인지 간략하게 살펴보겠다.
AI(Artificial Intelligence)이란?
- 지각능력을 인공적으로 구현하려는 컴퓨터 과학의 세부분야 중 하나이다. (출처: https://ko.wikipedia.org/wiki/인공지능)
- 사실 AI를 자세하게 살펴보면 아래 그림처럼 인공지능 > 기계학습(machine learning) > 딥러닝(Deep learning) 으로 구성이 되어있다.

- 보통 사람들은 인공지능 활용해서 OOO함. 이라고 말하는데 대부분은 딥러닝 모델을 말하는 것이다. (물론 머신러닝 기법도 사용한다는 사람도 있음…^^ 주관적인 생각)
- 딥러닝 모델이라고 말하면 여러 Task가 있지만 그 중에서 대표적으로 Object detection 분야 라고 지정하면 Yolo 계열 이라고 말할 수 있다.
- 나는 대학원 시절 국책연구과제로 local 환경에서 모델 개발 cycle은 데이터 수집, 레이블링, 아키텍처 설계(pre-trained사용 등), 학습모델 생성, 평가, 재학습 이렇게 사용을 해보았다.
- local환경에서 모델 개발 cycle을 하려면 하드웨어(GPU달린 컴퓨터), 딥러닝 프레임워크 선정 및 환경설정을 해줘야한다.
- 사용하기에는 편리하겠지만 그만큼 불편한 점이 있다. 불편한점은 하드웨어 구매할때 많은 비용이 발생, 공간 필요, 주기적인 관리, 과제가 끝났을 경우 사용하지 않으면 무용지물이 되어버리는 것이다.
- 그래서 해결방법으로는 클라우드 컴퓨팅시스템이다.

- 클라우드 컴퓨팅을 간략하게 말하면 IT리소스를 인터넷을 통해 온디멘디로 제공하고 사용한만큼만 비용을 지불하는 것이다.
- 대표적으로 AWS(Amazon Web Services), Microsoft Azure, Google Cloud Platform 이 있다.
- 클라우드 컴퓨팅을 이용하여 빠른 구축과 사용량만 비용을 내면 되기 때문에 연구 또는 APP 개발에 집중적으로 할 수 있는 장점이 있다.
- 이러한 환경을 이용하면서 딥러닝을 할 수 있는게 있다면 얼마나 좋을까?
- 그 해답은 바로 Amazon SageMaker이다.
Amazon SageMaker란?
- 비즈니스 분석가, 데이터 과학자, ML 엔지니어 들이 쉽고 빠르게 습득 할 수 있도록 지원해주는 클라우드 ML 플랫폼이다.
- 쉽게 이야기하면 ML을 하기위한 cycle인 데이터 준비, 모델 구축, 학습, 배포를 쉽고 빠르게 할 수 있는 것이다.

- SageMaker는 여러 기능들을 가지고 있다.
- No-code ML tools
- Amazon SageMaker Canvas : 코드가 필요없이 ML 모델 구축 및 예측
- Purpose-built data preparation tools
- Amazon SageMaker Data wrangler : 데이터 준비 및 처리
- Amazon SageMaker Feature Store : ML feature 저장, 검색 및 공유
- Amazon SageMaker Ground Truth Plus : ML에 필요한 효율적인 labeling 작업
- Amazon SageMaker Studio | Rstudio : 하나로 통합된 인터페이스
- → Jupyter notebooks로 사용하여 관리 및 협업 가능 → 모델 학습 튜닝 배포 까지 가능

- 간단하게는 이렇게 있으며 전체적인 기능은 밑에 그림처럼 되어있다.

- 이렇게 SageMaker에 수 많은 기능들 중에서 나는 SageMaker Canvas에 대한 것을 말해보겠다..!(SageMaker에 다른 기능들은 점점 하나씩 실습 해보고 스팅 예정..!)
Amazon SageMaker Canvas
- 코드 필요없이 ML 모델 구축 및 예측 모델 생성 할 수 있다.
- 또한 visualization이 잘 되어있어서 마우스 클릭으로만 해서 깔끔하게 볼 수 있다.
- 먼저 Canvas 실행
- Immersion Day 에서는 AWS Event engine을 이용하였다. (참고URL : https://catalog.us-east-1.prod.workshops.aws/workshops/80ba0ea5-7cf9-4b8c-9d3f-1cd988b6c071/en-US/0-prerequisites) → 여기 AWS Instructor-Led Lab 에서 OTP 로그인 하고 나서 Self-Paced Lab 참고하였음 ※ Event engine이기 때문에 OTP 접속을 하였지만, 일반적으로 사용하려면 프리 티어로 로그인 하면 SageMaker 2개월 무료 사용가능함! (SageMaker 시작은 Self-Paced Lab 참고)
- Canvas 실습
- Amazon SageMaker Canvas Immersion Day에 있는 예제를 따라해보겠다. (참고URL : https://catalog.us-east-1.prod.workshops.aws/workshops/80ba0ea5-7cf9-4b8c-9d3f-1cd988b6c071/en-US/7-supply-chain)
- 예제의 목표는 물류 회사에서 “발송물의 예상 도착 시간을 일수로 예측”하는 것을 해본다. 즉, regression 문제이다.
- 데이터는 Shipping Logs와 Product Description 파일이 있다.
- 먼저 데이터를 S3에 업로드하여, Canvas에 데이터를 로드 해야한다.

- 이후에 업로드 하기 위해 Datasets에서 import를 클릭한다!!



- 그 다음으로 Shipping Logs와 Product Description 데이터에는 “ProductId” 되어있는 것을 합쳐줘야한다. 이때 join data를 클릭하고 왼쪽에 DataSets에서 마우스로 끌고오면 된다. 이후 Save & close 클릭 후 Import data 클릭 하여 이름 지정(나는 Supply_join_data라고 하였음.) 을 해준다.

- 이렇게 마우스 클릭으로 아주 쉽게 두 .csv 파일을 하나로 합칠 수 있다. (python 코드로 한다면 각각 csv파일을 불러와서 list에 넣고 해당 index를 접근해서 맞는지 확인 후에 최종적인 list를 다시 저장 해야함.. 굉장히 불편하다… 코드를 모르는 사람은 못할수도있다.)

- 예측해야할 데이터를 만들었으니 이제는 ML 모델을 생성할 차례이다. 모델을 생성하려면 “create model”를 클릭 하여 모델 이름을 지정해준다.(나는 Supply_join_data_model 라고 함)

- 이후 어떤 target으로 예측할것인지를 선택해야한다. 이 예제에서는 발송물이 예상 언제 도착하는지 예측하는것이 목표이므로 해당 target은 “ExpectedShippingDays” column 이다.

- 여기서 model type을 변경 할 수가 있다. 그림과 같이 Time series forecasting(시계열 예측), Numeric model type(수치 예측)과 다른부분으로 2 category model(이진분류), 3+ category model type(다중분류) 로 선택할 수 있다.
- 이 예제에서는 수치 예측을 하는것으로 numeric model type으로 선택한다.
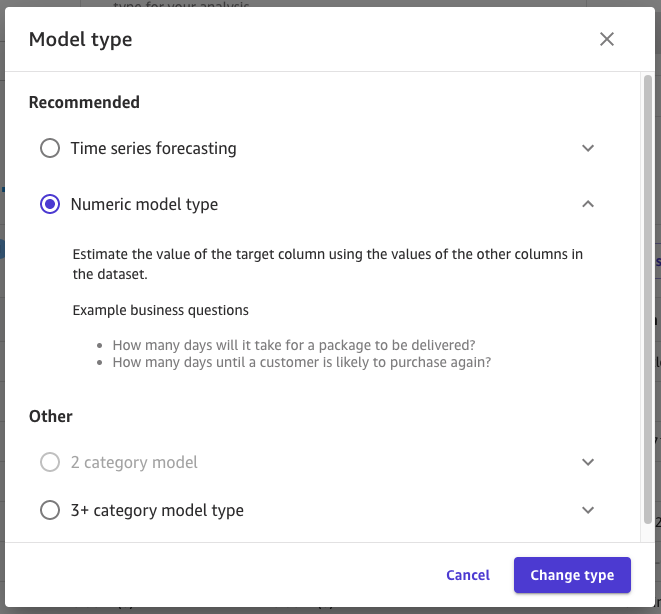
- 모델을 만들기 전에 해당 특징들을 선별(제거) 또는 추가를 해줘야하는 작업이 필요하다…!
- 이러한 작업들은 손 쉽게 마우스 클릭과 간단한 수식으로 구현이 가능하다.
- 실습에서는 XShippingDistance 와 YShippingDistance를 사용하여 거리에 대한 집계 측정값을 계산해보겠다.
- 그림 처럼 Functions을 클릭 후 유클리디안 거리 공식을 수식을 넣고 Add를 눌러주면 쉽게 거리 측정 계산하여 추가 할 수 있다.

- 아주 간단하고 쉽게 데이터 추가를 할 수가 있다. (너무 편리하다…!)
- 모델을 생성하기 위해서 불필요한 특징들은 제거 해주는게 좋다. Canvas에서는 불필요한 특징들을 제거 하는데 클릭 하나로 제거 할 수 있다.

- 그림 처럼 체크 박스를 통해서 클릭하면 drop 되어 지는것과 created distance로 아까 추가한것이 나온다. model recipe는 해당 특징(요소)들의 현황(추가 및 제거)을 보여준다.
- 이제 드디어 모델 학습이다~~~! (데이터 로드, 데이터 전처리 단계 까지 완료)
- 바로 학습을 해도 되지만, Canvas에서는 Preview model 기능을 제공한다.
- Preview model은 두가지 이점을 준다. A. 모델의 기본 성능을 제공(단, 실제모델은 이보다 더 성능이 좋다.) B. 특징(요소) 중요도에 대한 정보를 제공함 (이것은 모델을 만들때, 각 특징에 대한 얼마나 영향이 미치는지에 대한 정보를 알 수가 있다.)
- Preview model을 클릭해서 사용해보자!!
- 사용하기 전에 두 가지 버전으로 Preview model 하였을때, 변화하는지 봐보겠다. A. Drop(ProductId, OrderID, YShippingDistance, XShippingDistance, OrderDate), Create(distance), Extract(quarter, week of year, month from OrderDate) B. Drop(ProductId, OrderID, YShippingDistance, XShippingDistance, OrderDate, OnTimeDelivery, ActualShippingDays), Create(distance), Extract(quarter, week of year, month from OrderDate) → A, B 차이는 Drop에서 OnTimeDelivery, ActualShippingDays가 추가 된것 뿐이다. 즉, 특징(요소)를 불필요한것을 없앤것이다.

- 위 그림(A)과 아래 그림(B)을 비교해보면 아래 그림(B)가 성능은 더 안좋아졌지만 A에서 다른 특징(요소)들과 비교하면 ActualShippingDays가 너무 영향력이 커서 확실히 많은 차이를 볼 수 가 있다.
- 그래서 ActualShippingDays를 제거 하면 아래 그림(B)처럼 특징(요소)들의 차이가 그나마 적게 된것을 볼 수 있으며, 이것은 특징(요소)가 잘 분산 되어 알맞은 추론을 생성 할 것이다.
- 이제는 진짜 학습이다. 학습에서도 Quick build와 Standard build가 있다. A. Quick build : 정확도 보다는 속도를 우선적으로 하여 그만큼 하이퍼파라미터와 변수의 조합을 적게 사용함(2 ~ 15분 정도 걸림) B. Standard build : 속도보다는 정확도를 우선적으로 하여 그만큼 하이퍼파라미터와 변수의 조합을 많이 사용함(2 ~ 4시간 정도 걸림)

- 나는 Quick build 말고 Standard build로 진행 하였다.

- 예제에 나와있는 것과 다르게 standard build를 한 경우가 더 좋게 결과가 나왔다. (실제로 했을 때, 각각 다르게 결과가 나올 수도 있다. 이것은 머신러닝이 학습하면서 약간의 확률을 도입하여 빌드마다 다른 결과 보여주는 것이다.)
- 학습결과는 보면 InBulkOrder가 모델 생성에서 가장 영향력이 있는 특징(요소)라고 볼 수 있다. column impact를 보면 순서대로 영향력이 얼마나 되어있는지 나열 되어있다.
- 학습된 결과로 예측을 해보도록 하겠다…!
- 예측할 데이터는 join data로 했던 Supply_join_data를 사용한다.

- 예측 결과는 12.061 RMSE 결과를 얻을 수가 있다. 해당 결과는 download 버튼을 사용하여 CSV 파일로 받아서 볼 수도 있다!
- 추가적으로 Canvas에서 할 수 있는걸 소개 하겠다!! 데이터에 대한 visualization(시각화)이다.
- 사용방법은 그림과 같이 Scatter plot, Bar chart, Box plot 형태로 사용할 수 있고 Columns에서 X축과 Y축에 어떤 데이터를 볼것인지 마우스로 드래그 하면 된다! 아주 간편하다.

- SageMaker Canvas 사용 후기
- 데이터 로드, 전처리, 시각화, 모델 학습, 예측 이렇게 전체적인 플로우를 python기반이 아닌 Canvas에서 할 수 있다는게 굉장히 편리하였다.
- 특히 데이터 로드 이후 전처리 단계에서 특징(요소)를 추가 하거나 제거 하는 부분은 엄청나게 쉬웠다. 마우스로 클릭하여 제거를 할 수있고 다른 요소를 추가할 때 Functions 에다가 수식 입력 하고 Add 버튼으로 추가가 되었다. python에서 했으면 list를 만들고 변수에 넣고 복잡한 과정이 필요했을 것이다.
- 모델 학습도 Auto ML이 있어서 알맞은 ML 모델로 학습하고 예측도 편리하였다.
- 제일 좋았던건 시각화 였다…! 이건 너무나도 잘 되어있었다. 바로바로 보여주기가 가능했다.
- 이렇게 SageMaker Canvas는 비즈니스 분석가들이 사용하도록 만든 기능이라고 한다. 코드가 필요없고 데이터를 빠르게 분석하고 싶으면 시간절약과 빠른 도입이 가능할 것으로 보인다.
- 다음으로는 SageMaker에서 다른 기능들을 실습하보고 다시 포스팅 하겠다~~!
'AWS > 기능 소개 및 에러처리' 카테고리의 다른 글
| [AWS Ec2] Failed to connect to your instance, Error establishing SSH connection to your instance 에러 해결법 (1) | 2023.06.26 |
|---|---|
| AWS Cloud9 과 streamlit을 활용한 이미지 분석 기능 구현 (0) | 2023.05.22 |
| DNN학습에서의 AWS EC2 g4dn xlarge vs 2xlarge 성능 및 과금비교 (1) | 2023.04.18 |
| AWS 모니터링을 위한 Slack 연동(with AWS lambda, CloudWatch) (6) | 2023.01.30 |
| AWS Slack으로 Monitoring 중 invaild_payload 오류 해결법(Window) (1) | 2023.01.27 |



